
仓网规划在供应链设计中至关重要,规划的质量好坏,对企业的物流费用有直接的影响。在快消、汽配等行业,一家营业额百亿的企业,物流成本可能就占了十亿,而通过仓网的优化,可以将物流成本降低百分之十几以上,对企业的盈利能力产生决定性的影响。
不同的企业在谈论仓网规划时,由于供应链复杂度不同、公司所处的发展阶段不同,背后的精确含义是不同的,我们在文章下面的部分会例举几个常见的场景。但不管是哪种场景,仓网规划的目的都是要回答两个问题:
- 仓库应该放在什么位置?这是选址问题。
- 仓库和客户、以及工厂和仓库之间,要建立怎样的服务与被服务的对应关系?这是个分配问题。
不管是建新仓、关仓,还是搬仓,都需要回答选址和分配问题。但是,在不同的情景下,回答这些问题所用到的数据分析方法,是不同的。
所谓绿地分析,英文叫greenfield analysis,就是在一片长满绿色杂草的空地上去做规划。也就是说,已经知道某个区域的客户的分布,但是这个区域一个仓都还没有,需要找到合适的位置,建设新仓来服务该区域。
这样的需求在成长型的企业很普遍。例如,一个从川渝地区成长起来的企业,客户逐渐遍布全国,就要考虑在华北、华东等地建新的区域仓。在成熟期的企业中,当要变革运输模式时,也有相似需求。比如一个汽配公司原本都是从工厂直发到客户,这样的坏处是散货多,所以想要建立区域仓,在厂到仓之间采取干线集运的方式,大大节省物流费用。
在做绿地分析时,最重要的数据是客户的地理位置,以及预测的每个客户的需求量。需求量一般以吨或者立方米来表示。其次,还要估计新仓的建设和运营费用。在有些情况下,还要知道其它约束条件,比如最大的库容量、允许的最大服务半径等。常用的分析方法,是先将客户进行聚类,把距离近的客户放在一组,再在每一组中使用重心法找到合适的位置来建新仓。
算法一般有能力找到最佳的新仓个数,多于这个数或者少于这个数,对应的总体成本就会增加。这里的总体成本包括了仓到客户的运输费用,以及每个仓的建设运营成本。算法的输出是一系列新仓的经纬度,根据经纬度可以解析最近的邮政地址。
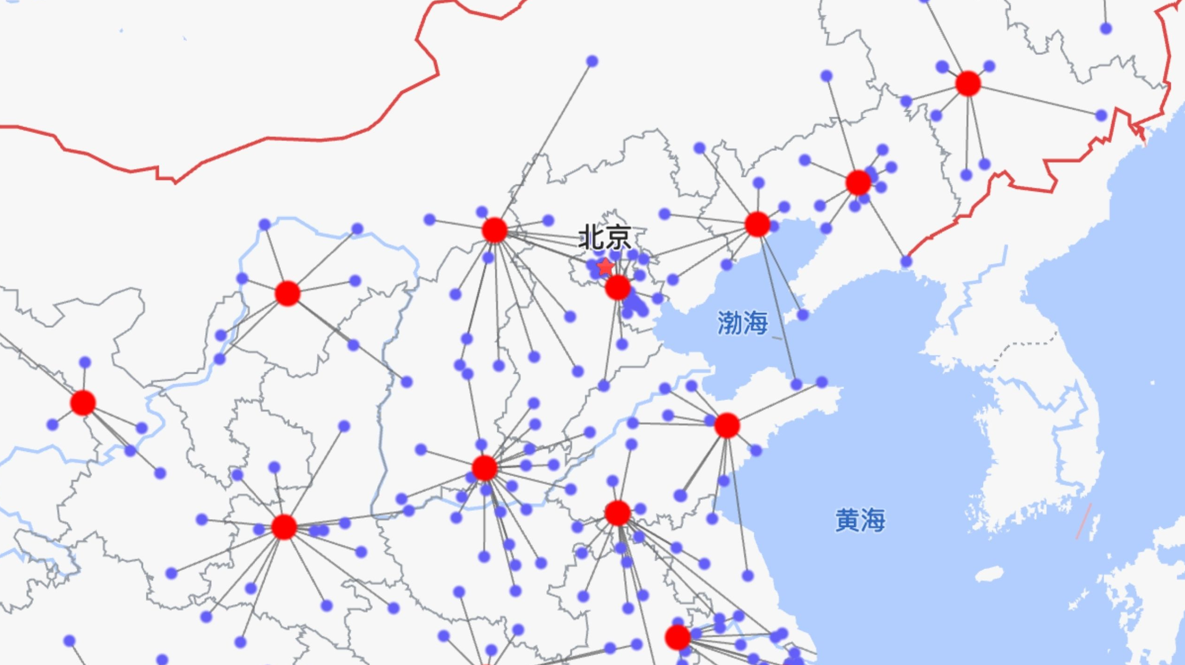
使用重心法找到合适的位置
拿到上一步得到的新仓的经纬度,业务人员会以此为中心,寻找附近的物流园区。这时要考虑附近的交通条件、招工难度等因素,因此可能会多找几个备选方案。如果目标是建三个新仓的话,可能会找到十个园区,从中间选择三个。
应该要从中选择哪几个,才能实现最低成本的目标呢?从十个选三个,就有一百二十种组合。对于每一种组合,还要考虑仓和客户的最佳匹配关系,仓容量、服务半径等约束条件,以及调用地图API获取每条运输线路的实际公路驾驶距离。这样下来,计算量动辄就达到千万以上,必须依靠优化算法,才能在合理的时间内,找到最优的仓库组合。
还有更复杂、但是很常见的情况,是仓网中既有新仓,又有原有仓。比如原本在长沙、合肥有两个仓服务全国,现在要在华北新增一个区域仓。原本由长沙、合肥仓服务的客户,势必有一部分要转给新的仓。那么在决定新仓位置时,就须要把老仓和全国客户也一起放在模型里计算,得到的结果才是全局最优的仓网结构。
上面的场景中,只考虑了单层的仓库网络,也只考虑了从仓到客户的服务距离与成本。还有一种更复杂的场景,比如零售和餐饮行业常有的中心仓CDC和区域仓RDC两层仓网,在选址时就还要考虑仓与仓之间的联动关系。
举一个在汽车配件领域的例子。配件厂运输产品到汽车主机厂,一般走直发的模式,就是每个配件厂要找车把货运到每个主机厂。如果有五十个配件厂,二十个主机厂,就有一千条运输线路,每条线上的货量很分散,只能用小货车装载。
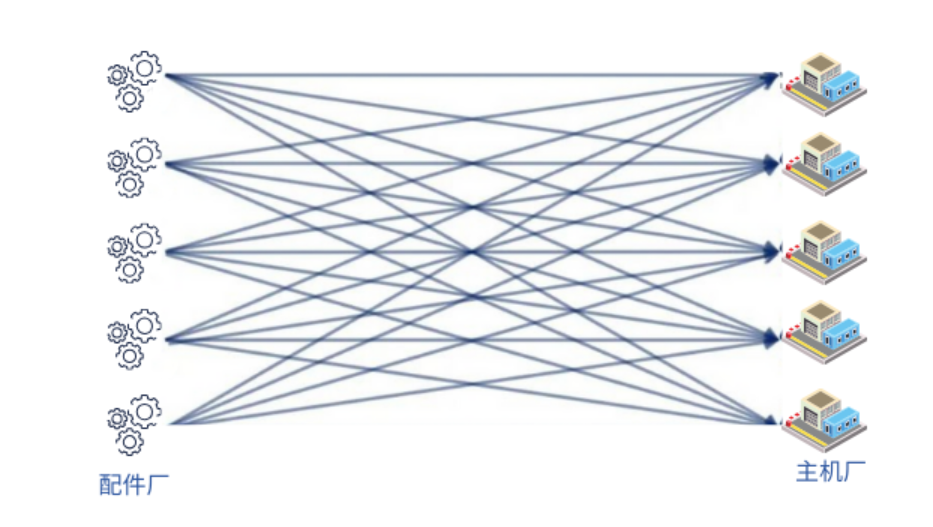
由于配件厂产业带集中在几个区域,如果在配件厂周围建集运仓,在主机厂附近建区域仓,那么就可以将远途干线运输线路降至一百条以内,货量相应更加集中,能够发挥规模运输优势,把物流费用降低。
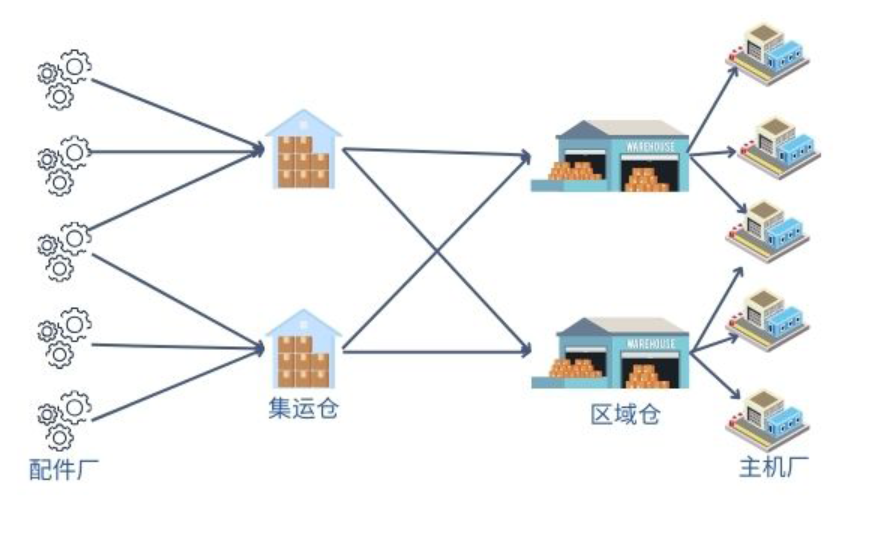
在这种场景下,怎样决定集运仓和区域仓的数量和位置,就是一个更加复杂的挑战。在这方面有不同的选址算法,有的先决定集运仓,再决定区域仓,有的算法反过来,还有的算法一次性计算出整体方案。具体选择哪个算法,要根据问题的实际情况来决定。
确定了仓的位置和分配关系,并不是工作的终结。企业的生产布局会变,客户的需求分布也会在不同地区间此消彼长。随着这些变化,原本优化好了的仓网布局和分配关系,可能已经不是最优的。
另外一个挑战,是库存在不同仓之间的分布,并不总是合理的。比如长沙仓的库存可能不够,无法满足它服务的客户的需求,而合肥仓的库存又太多。
以上的情况,都需要重新调整仓和客户的分配关系,让整个网络回到优化的状态。这样的调整需要根据实时的供需数据,以及承运合同的现实情况来决定。只有借助数智化工具,才能实现这种高频以及人工Excel已经无法计算的优化需求。
降低全社会物流成本,对国家和对企业都是至关重要的。利用数智化工具,对仓网进行合理规划,是降低物流成本的重要途径。